经典RCU在临界区内不能睡眠或阻塞,因此SRCU(Sleepable RCU)被提出允许在读者的临界区内睡眠。为了尽量避免在临界区内睡眠导致的RCU callbacks积压,SRCU采用了域隔离,即使出现RCU callbacks积压,也只影响当前域的SRCU。
SRCU核心数据结构

-
每一个srcu域一个srcu_struct,其中sda是per-cpu变量。srcu_idx是用来判断读取或修改srcu_lock_count/srcu_unlock_count时访问哪个数组元素,可以处理srcu的不同GP。
-
每个srcu_struct都有一个per-cpu的srcu_data数据结构,记录了对应srcu域的数据信息,其又与一个srcu_node关联。
-
所有的srcu_node根据CPU拓扑被组织成一棵树,以数组形式存储在srcu_usage数据结构中,具体实现见rcu_init_geometry()。
-
srcu_usage保存此srcu相关的一些统计信息。
SRCU常用API
-
srcu_read_lock():标志读临界区的开始,增加当前cpu上的srcu_lock_count计数。
-
srcu_read_unlock():标志读临界区的结束,增加前cpu上的srcu_unlock_count计数。当所有CPU上对应的srcu_lock_count与srcu_unlock_count相等时,即所有CPU都已不在此srcu的读临界区内。
-
synchronize_srcu():写者修改完数据后同步srcu,本质上是调用call_srcu()将srcu处理回调入队后开启并等待Grace Period结束后其被调度运行并完成。
SRCU Grace Period
每个Grace Period用一个唯一的序列号来标识,低两位编码为Grace Period的相关处理状态。当低两位都为零,则标识当前没有尚未完成的GP。状态被编码到srcu_usage结构体的srcu_gp_seq变量中,因此每个GP序列号是4的倍数。内核定义了这样一些状态:
#define SRCU_SNP_INIT_SEQ 0x2 // SRCU节点初始化时设置
#define SRCU_STATE_IDLE 0 // 没有SRCU GP正在运行
/* State set by rcu_seq_start(). Indicates we are scanning the readers on the slot
defined as inactive (there might well be pending readers that will use that
index, but their number is bounded). */
#define SRCU_STATE_SCAN1 1
/* State set manually via rcu_seq_set_state(). Indicates we are flipping the readers
index and then scanning the readers on the slot newly designated as inactive (again,
the number of pending readers that will use this inactive index is bounded). */
#define SRCU_STATE_SCAN2 2
#define RCU_SEQ_CTR_SHIFT 2
#define RCU_SEQ_STATE_MASK ((1 << RCU_SEQ_CTR_SHIFT) - 1)
rcu_seq_state()根据序列号获取当前SRCU的状态。
static inline int rcu_seq_state(unsigned long s)
{
return s & RCU_SEQ_STATE_MASK;
}
在开启一个新的srcu GP时,会将状态设置为SRCU_STATE_SCAN1。
rcu_seq_start(&ssp->srcu_sup->srcu_gp_seq);
在GP结束时,将状态重新置为SRCU_STATE_IDLE,即srcu_gp_seq被设置为下一个被4整除的数。
static inline unsigned long rcu_seq_endval(unsigned long *sp)
{
return (*sp | RCU_SEQ_STATE_MASK) + 1;
}
SRCU callbacks
SRCU采用了分片的回调链表来管理SRCU的callbacks,将回调分成了四个部分:
-
[head, *tails[RCU_DONE_TAIL]): GP已过,可以触发的回调;
-
[*tails[RCU_DONE_TAIL], *tails[RCU_WAIT_TAIL]):当前CPU上正在等待当前GP结束正在等待的回调;
-
[*tails[RCU_WAIT_TAIL], *tails[RCU_NEXT_READY_TAIL]):当前CPU上在下个GP开始前抵达的回调;
-
[*tails[RCU_NEXT_READY_TAIL], *tails[RCU_NEXT_TAIL]):下一个GP开始后可能抵达的回调。
#define RCU_DONE_TAIL 0 /* Also RCU_WAIT head. */
#define RCU_WAIT_TAIL 1 /* Also RCU_NEXT_READY head. */
#define RCU_NEXT_READY_TAIL 2 /* Also RCU_NEXT head. */
#define RCU_NEXT_TAIL 3
#define RCU_CBLIST_NSEGS 4
struct rcu_segcblist {
struct rcu_head *head;
struct rcu_head **tails[RCU_CBLIST_NSEGS];
unsigned long gp_seq[RCU_CBLIST_NSEGS];
#ifdef CONFIG_RCU_NOCB_CPU
atomic_long_t len;
#else
long len;
#endif
long seglen[RCU_CBLIST_NSEGS];
u8 flags;
};
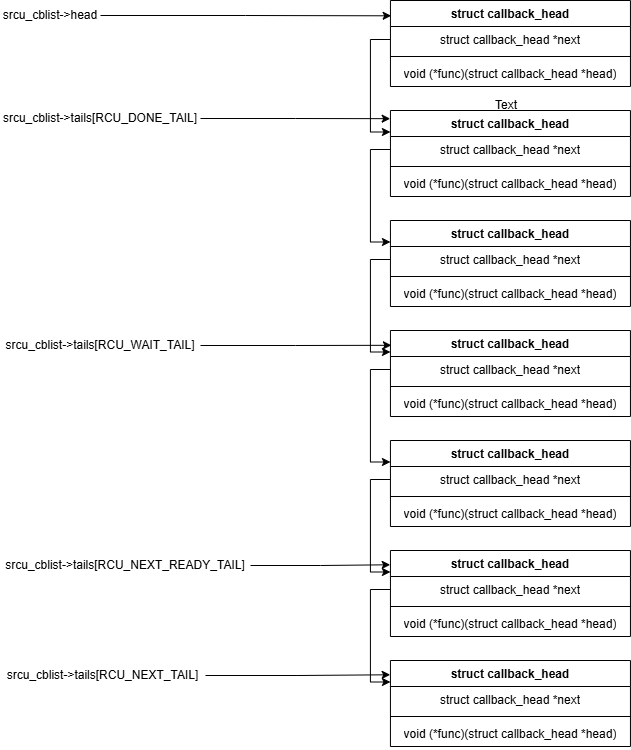
当写者修改完数据需要做srcu同步时,会将rcu_head挂到srcu_data结构体的srcu_cblist里。
void rcu_segcblist_enqueue(struct rcu_segcblist *rsclp,
struct rcu_head *rhp)
{
rcu_segcblist_inc_len(rsclp);
rcu_segcblist_inc_seglen(rsclp, RCU_NEXT_TAIL);
rhp->next = NULL;
WRITE_ONCE(*rsclp->tails[RCU_NEXT_TAIL], rhp);
WRITE_ONCE(rsclp->tails[RCU_NEXT_TAIL], &rhp->next);
}
SRCU工作队列
内核创建了一个名为rcu_gp的工作队列处理srcu。
rcu_gp_wq = alloc_workqueue("rcu_gp", WQ_MEM_RECLAIM, 0);
在初始化srcu结构体时,注册了工作队列被唤醒后的srcu GP处理函数process_srcu()。
INIT_DELAYED_WORK(&ssp->srcu_sup->work, process_srcu);
process_srcu()里做的事情主要是更新srcu的GP状态,并根据队列里是否还有等待的srcu回调需要处理来决定是否继续调度工作队列来处理。其中,srcu_advance_state()负责推进GP状态机的更新,根据状态来开启或关闭GP。当读者均已离开临界区后,调用srcu_gp_end()结束GP。在srcu_gp_end()里,调用srcu_schedule_cbs_snp()在指定CPU上调度rcu_gp_wq工作队列执行srcu回调。
/*
* Schedule callback invocation for all srcu_data structures associated
* with the specified srcu_node structure that have callbacks for the
* just-completed grace period, the one corresponding to idx. If possible,
* schedule this invocation on the corresponding CPUs.
*/
static void srcu_schedule_cbs_snp(struct srcu_struct *ssp, struct srcu_node *snp,
unsigned long mask, unsigned long delay)
{
int cpu;
for (cpu = snp->grplo; cpu <= snp->grphi; cpu++) {
if (!(mask & (1UL << (cpu - snp->grplo))))
continue;
srcu_schedule_cbs_sdp(per_cpu_ptr(ssp->sda, cpu), delay);
}
}
