最近工作中经常遇到设备直通方面的问题,各云厂商为了在虚拟机内部达到接近裸机的I/O性能,通常将物理设备比如网卡、NVMe等直通到虚拟机内。本文基于Linux Kernel 6.6及QEMU 8.2分析基于VFIO的设备直通实现。
VFIO概述
VFIO(Virtual Function I/O)是Linux内核提供给用户态应用直接访问物理设备的框架,与具体的IOMMU或设备硬件无关,虚拟化场景下基于VFIO可以将物理设备直通到虚拟机内部以使虚拟机内获得与物理机下等同的I/O性能。不同于此前的UIO(Userspace I/O),VFIO使得用户态驱动更安全。
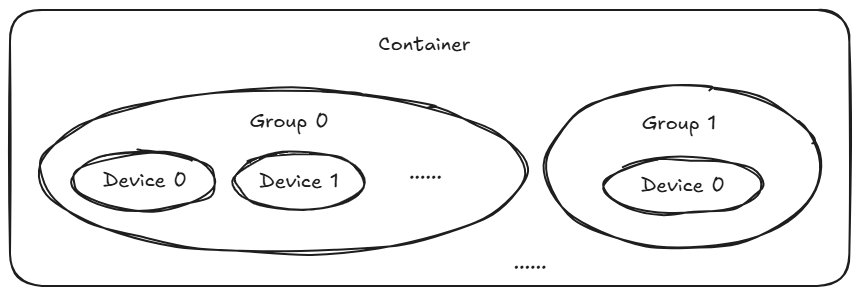
之所以安全,是因为当前VFIO整合了针对IOMMU的支持。IOMMU限制了设备可以访问的内存地址空间,设备之间可以做到互相隔离。然而设备隔离的粒度也并不总是以设备为粒度,例如PCI桥下的设备都属于一个IOMMU组,它们都被隐藏在这个桥下面,对于IOMMU硬件来说只能看到这个桥。因此IOMMU组是IOMMU中隔离的最小单元,多个IOMMU组可以共享同一份IOMMU页表。共享同一份IOMMU页表的多个IOMMU组或者设备,属于同一个container。
VFIO软件栈
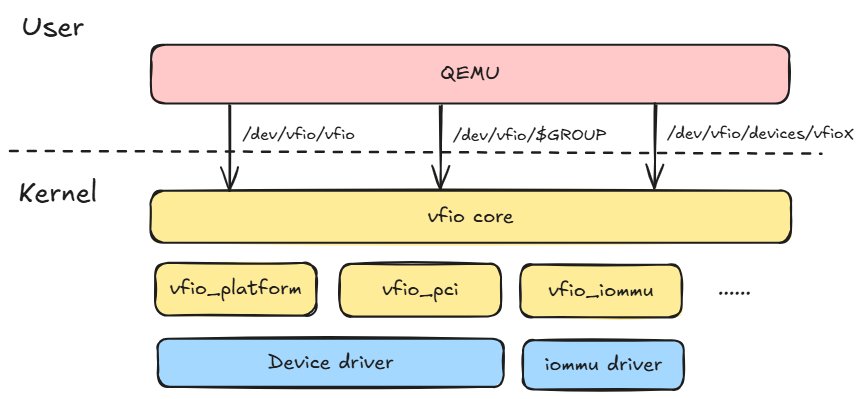
内核VFIO框架面向用户态暴露了三类设备文件:
-
/dev/vfio/vfio:打开设备文件即为创建一个container。提供的ioctl命令包括:
-
VFIO_GET_API_VERSION:获取API版本号。
-
VFIO_SET_IOMMU:设置IOMMU类型。
-
VFIO_CHECK_EXTENSION:检查VFIO支持的IOMMU类型。
-
VFIO_IOMMU_GET_INFO:获取IOMMU相关信息。
-
VFIO_IOMMU_MAP_DMA:创建GPA与HPA的IOMMU页表映射。
-
VFIO_IOMMU_UNMAP_DMA:解除GPA与HPA的IOMMU页表映射。
-
VFIO_IOMMU_DIRTY_PAGES:配置脏页跟踪。
-
-
/dev/vfio/$GROUP:直通设备需要先解绑原有的驱动,再绑定vfio驱动。绑定vfio驱动后,会将设备加入对应的group,生成对应的group设备文件。用户态通过VFIO_GROUP_SET_CONTAINER这个ioctl将group加入指定的container。注意,只有当iommu组下所有的设备都绑定vfio驱动后,应用程序才能通过此设备文件管理此vfio的group。提供的ioctl命令包括:
-
VFIO_GROUP_GET_DEVICE_FD:获取设备的文件句柄。
-
VFIO_GROUP_GET_STATUS:获取VFIO组的状态,只有当对应IOMMU组内所有设备都绑定了VFIO后状态才是正常的。
-
VFIO_GROUP_SET_CONTAINER:设置指定VFIO组所属的container。
-
VFIO_GROUP_UNSET_CONTAINER:解除指定VFIO组与container的绑定关系。
-
-
/dev/vfio/devices/vfioX:使用IOMMUFD框架能力提供的一个接口,用户态可以通过打开这个设备文件来直接获取设备的fd。提供的ioctl命令包括:
-
VFIO_DEVICE_BIND_IOMMUFD:将设备与指定iommufd进行绑定。
-
VFIO_DEVICE_ATTACH_IOMMUFD_PT:将设备加入指定的IOAS。
-
VFIO_DEVICE_DETACH_IOMMUFD_PT:将设备从指定的IOAS中移除。
-
VFIO_DEVICE_FEATURE:设置、检索和探测设备的features。
-
VFIO设备提供的其他控制命令
-
VFIO_DEVICE_GET_INFO:获取设备信息,region数量、irq数量等。
-
VFIO_DEVICE_GET_IRQ_INFO:获取设备中断信息。
-
VFIO_DEVICE_GET_PCI_HOT_RESET_INFO:获取PCI设备hot reset信息。
-
VFIO_DEVICE_GET_REGION_INFO:获取BAR/ROM/配置空间区域信息。
-
VFIO_DEVICE_IOEVENTFD:设置ioeventfd。
-
VFIO_DEVICE_PCI_HOT_RESET:设置PCI设备 hot reset。
-
VFIO_DEVICE_RESET:复位设备。
-
VFIO_DEVICE_SET_IRQS:完成中断相关的设置。
-
-
QEMU中的VFIO实例化
在QEMU里VFIO设备模型分为PCI和platform两大类,下文主要分析vfio-pci设备类型的实例化。
vfio_realize()
--> vfio_attach_device()
--> vfio_populate_device()
--> pread(fd, config, size, offset)
--> vfio_add_emulated_word()
--> vfio_pci_size_rom()
--> vfio_bars_prepare()
--> vfio_msix_early_setup()
--> vfio_bars_register()
--> vfio_add_capabilities()
--> vfio_migration_realize()
- vfio_attach_device()
首先将设备加入对应的group,如果已经创建则直接加入已创建的group。container保存在某个根AddressSpace中,所有的根AddressSpace由全局变量vfio_address_spaces记录。一个VFIOAddressSpace可以拥有多个container。QEMU通过VFIO_GROUP_SET_CONTAINER将指定的group设置加入指定的container中。
typedef struct VFIOAddressSpace {
AddressSpace *as;
QLIST_HEAD(, VFIOContainer) containers;
QLIST_ENTRY(VFIOAddressSpace) list;
} VFIOAddressSpace;
- vfio_populate_device()
接着对从vfio获取的设备信息做一些合法性检查后初始化regions,包括BAR空间、ROM空间以及配置空间等。vfio_get_region_info()根据指定的region索引获取对应region的大小、标志位、偏移量等信息。
for (i = VFIO_PCI_BAR0_REGION_INDEX; i < VFIO_PCI_ROM_REGION_INDEX; i++) {
char *name = g_strdup_printf("%s BAR %d", vbasedev->name, i);
ret = vfio_region_setup(OBJECT(vdev), vbasedev,
&vdev->bars[i].region, i, name);
g_free(name);
if (ret) {
error_setg_errno(errp, -ret, "failed to get region %d info", i);
return;
}
QLIST_INIT(&vdev->bars[i].quirks);
}
ret = vfio_get_region_info(vbasedev,
VFIO_PCI_CONFIG_REGION_INDEX, ®_info);
if (ret) {
error_setg_errno(errp, -ret, "failed to get config info");
return;
}
内核vfio_pci模块将各个region分布在指定的偏移量上,偏移量为VFIO_PCI_INDEX_TO_OFFSET(index)。
#define VFIO_PCI_OFFSET_SHIFT 40
#define VFIO_PCI_INDEX_TO_OFFSET(index) ((u64)(index) << VFIO_PCI_OFFSET_SHIFT)
VFIO框架在首次打开设备的时候会将直通的物理设备的真实BAR空间映射到内核虚拟地址空间,当BAR空间小于页大小且不对页对齐的情况下不支持QEMU执行mmap。QEMU将设备的BAR空间mmap进QEMU的虚拟地址空间后,会将这部分地址空间注册到KVM中。当虚拟机内部读写设备的BAR空间时就不会触发MMIO的陷出,从而获得较高的性能。vfio_region_setup()里就是QEMU通过VFIO_DEVICE_GET_REGION_INFO获取region相关信息后,创建MemoryRegion并注册该region的读写方法vfio_region_ops。如果该region不支持mmap则当虚机内部访问这块区域时陷出时调用的读写接口,针对设备句柄执行pread()/pwrite()。否则,初始化VFIORegion的mmaps数组。
- 配置空间
设备的PCI配置空间并没有像BAR空间那样支持QEMU的直接映射,一方面出于安全考虑不允许虚机直接读写物理设备的配置空间,另一方面QEMU也可以隐藏或者扩展部分配置。因此,QEMU做了一层拦截。当虚机读写设备配置空间时都将陷出到QEMU,QEMU通过读写设备文件句柄读写实际设备的配置空间。
- vfio_pci_size_rom()
ROM空间与配置空间类似,虚拟机内需要陷出进行读写访问,注册的读写接口为vfio_rom_ops。
- vfio_bars_prepare()
初始化VFIOPCIDevice的bars数组,通过设备句柄获取物理设备的BAR空间类型、大小等。
- vfio_msix_early_setup()
MSI-X table指向的BAR空间为了安全等原因,可能并不被支持被mmap映射,需要特殊处理。如果MSI-X表不允许虚机内部直接读写访问,则在QEMU侧进行模拟。
- vfio_bars_register()
注册BAR空间并mmap映射BAR空间到QEMU进程的虚拟地址空间。
- vfio_add_capabilities()
添加设备的PCI capabilities并进行初始化,例如初始化MSI-X。
- vfio_migration_realize()
初始化热迁移。
DMA重映射
物理机下设备DMA需要通过IOMMU将IOVA翻译成HPA,在设备直通的虚拟化场景下则需要将GPA翻译为HPA。如上文所述,QEMU在注册设备的BAR空间区域时会通过VFIO_IOMMU_MAP_DMA这个ioctl命令创建IOMMU页表映射。
中断重映射
中断重映射比较复杂,即将物理设备的中断投递到虚拟机内部。分以下三种情况;
-
对于不支持MSI/MSI-X中断重映射表的情况,VMM介入比较多,先在GSI全局中断表拦截兼容MSI中断,然后通过irqfd向虚拟机注入中断。中断会打断一个物理CPU处理,然后不一定是对应VM的vCPU,性能最差。
-
支持MSI/MSI-X中断重映射表,通过查找IRTE会重新生成一个新中断,如果绑定了CPU,发送给对应的vCPU上,然后注入中断。
-
post interrupt :中断直接注入VM中。思想就是软件负责配置,剩下硬件自动处理,由于VM exit少,性能最接近native。
参考资料
[1] VFIO - “Virtual Function I/O” — The Linux Kernel documentation
